
The prevailing narrative around AI-assisted development is that the technology has democratized software creation. That anyone with a prompt can ship a product. This is wrong in a way that matters.
What AI has done is eliminate the translation layer between domain expertise and working software. That's a significant shift, but it rewards depth, not access. The people who will build durable products with these tools are the ones who already know what should exist and why. AI doesn't replace the thinking. It accelerates the execution.
I've spent 25 years in digital streaming and media — Rhapsody, BitTorrent, CNET, the original Napster, my own Otter Network — building, operating, and advising content platforms. I understand how these systems work at an infrastructure level. What I am not, and have never been, is a software developer.
In January 2026, I shipped Ghost Guide, a production streaming discovery platform for genre films with over 15,000 titles, real-time streaming availability across 200+ services, an AI-powered recommendation engine, and programmatic SEO generating thousands of unique film pages. I built it using Claude Code, Anthropic's command-line coding tool, as my entire engineering team.
This is a build diary. Not a hype piece, not a product demo: this is a methodical account of what worked, what failed, and what the process reveals about how AI changes the relationship between expertise and execution. The methodology is what makes this replicable.
The Problem
I run a Substack called Ghosts in the Machine where I write about horror and genre cinema. Roughly 950 subscribers; a serious, literate audience. The same question surfaced every week in different forms: Where can I actually watch this?
Streaming had fragmented into dozens of services and models — SVOD, VOD, FAST channels, linear — and no one was building a guide that treated genre content with editorial seriousness. Letterboxd is a social network. JustWatch is a utility built on a marketing data business. Apple TV is incomplete. None of them combine editorial curation with real-time streaming availability and the kind of genre literacy this audience expects.
I was convinced the browsing experience I remembered from record and video stores — the thrill of discovery through physical proximity to things you didn't know existed — could be replicated in a digital interface. I'd been thinking about content discovery platforms for two decades. I knew what this product should be. I couldn't build it.
Until the tools caught up with the expertise.
The Ground Rule
Before the build specifics: this approach only worked because I already knew what I wanted to build.
I could evaluate whether a data model was right because I've lived inside content platforms. I could identify when a UI decision was wrong because I've designed streaming experiences. When Claude proposed an architecture, I wasn't accepting it blindly: I was evaluating it against 25 years of pattern recognition.
The working model that emerged was clear: I operate as product owner and editorial director. Claude operates as an engineering team. I make every product decision. Claude implements them.
Without domain expertise, AI builds something generic. With it, AI becomes a force multiplier unlike anything I've encountered in my career. That distinction is the entire thesis.
Phase 1: Planning (Zero Lines of Code)
The most consequential mistake in AI-assisted development is jumping straight to code. The instinct is understandable. The tool is right there, ready to generate. Resist it.
I spent the first phase producing four documents. Those documents are the reason the project succeeded.
The Strategic Analysis
I started by using Claude as a strategic co-founder. I described the problem space: streaming fragmentation, discovery fatigue, the genre content gap, and asked for a full evaluation.
The output included five data providers ranked by speed-to-market and cost, competitive landscape mapping, three business model options, and a phased roadmap. I validated the provider recommendations through industry contacts and confirmed that streaming metadata is expensive. Which made Claude's suggestion of Watchmode, with its developer-first API and affordable pro tier at $249 for the first month, a critical early decision.
The analysis produced a single sentence that guided every subsequent choice: the competitive wedge couldn't be aggregation. Everyone aggregates. The wedge had to be multi-mode discovery, curation people trust, and speed.
Two foundational decisions came from this conversation. First, Watchmode as the data provider — credit-based, roughly 1,000 free credits per month. That budget constraint would later force one of the project's best design decisions. Second, the core data model: what I call the Availability Card, a single object representing every title with its metadata, streaming sources, ratings, and editorial tags. One entity, one row, everything attached. This was conceived as a product concept before it became a database schema, and that sequence matters.
The PRD
The strategic analysis became a 15-page Product Requirements Document. It contained an executive summary, five core interfaces with wireframe layouts, a full data architecture with TypeScript interfaces, user personas, UI/UX specifications down to hex color codes, and a six-week milestone plan.
Five interfaces were defined: a live TV EPG with genre highlighting, a sequential viewing grid for franchise viewing, an on-demand browser with filtering and large poster images, curated editorial lists, and an admin CMS. All five shipped.
The PRD also documented what we were not building: no genres outside horror, sci-fi, and dark thriller. No mobile apps. No in-app playback. No social features. No recommendation algorithms at launch. Editorial-first. These constraints weren't limitations, they were the product strategy.
Perhaps most importantly, the PRD established a hard budget constraint: pre-cache roughly $50 worth of horror catalog within 1,000 free Watchmode API credits. This single constraint forced the priority-based enrichment system that became one of the project's most elegant features — a database flag called --in-lists that ensures curated titles get enriched first while the long tail waits.
The Wireframe Document
A separate visual design specification described the aesthetic, screen anatomy, interaction patterns, color system, and responsive breakpoints. Some shipped as designed. Some evolved: the wireframe specified a right-side detail drawer; we built a modal overlay instead. The colors changed. That's expected. Specifications are navigation aids, not contracts.
The Implementation Guide
This is the document I'd point anyone to who wants to replicate this approach. Claude produced a 10-phase build plan written specifically for a non-coder. Each step includes the literal prompt to type into Claude Code, what Claude will do in response, and how to verify it worked.

The prompt structure that emerged follows a consistent pattern: "Create a [component] at [file path] that: [numbered list of requirements]." The specificity is the skill. "Build me a movie card component" produces generic output. "Create a TitleCard at src/components/TitleCard.tsx that accepts an AvailabilityCard prop, displays a 2:3 aspect ratio poster with a fallback placeholder, shows service badges using specific hex colors per streaming platform, and has a hover effect with slight scale plus glow on a #242424 background" produces something you can ship.
The takeaway from Phase 1: Four documents. Zero code. Roughly a week of focused thinking. Every hour spent here saved ten hours during the build.
A note on middleware: this is where the unglamorous but essential work happens. Hosting (Vercel), database (Supabase), authentication, email services — each requires configuration and produces API keys that allow the product to communicate with external services. This infrastructure work is sequential, detail-oriented, and must be right before code begins.
Phase 2: The Build
What 112 Commits in 10 Weeks Looks Like
The git history tells the real story.
January 18: Initial commit. First deploy to Vercel. Immediate build errors and a browser crash. Four commits on day one, two of them fixes.
January 19: The inflection point. 25 commits. Pluto TV EPG integration using open-source programming data, home page design, streaming source display, Row Level Security bypass routes, poster images. The application stopped being a skeleton and became a product.
January 20–24: Infrastructure buildout. Admin tools, watchlist functionality, trailer integration, research URL integration, community lists. Authentication begins breaking.
January 26: The authentication crisis. 12 commits in one day, every one about auth. This failure deserves its own section.
January 28–31: SEO buildout. Film detail pages with structured data, dynamic sitemap, Incremental Static Regeneration. Also where I began writing handoff documentation, a practice that became essential to the workflow.
Handoff documentation addresses a fundamental limitation: Claude Code sessions start fresh with no memory of prior work. At the end of each session, I ask Claude to compile a handoff document in markdown, a summary of the day's work in language the model can parse efficiently in the next session. I later standardized this with an /init command at session start that reads the full codebase, summarizes it, and generates a CLAUDE.md file establishing context. Without this practice, the first 30 minutes of every session is re-explanation. With it, you're productive in seconds.
February: Stabilization. Analytics, Search Console configuration, framework upgrades, ad integration.
March: Ghost Host AI recommendation feature. Brand refresh. New editorial lists.
Total active build days: roughly 20. Not consecutive; this was built around a full client workload.
Seeding 10,000 Films
The data pipeline is one of the project's most instructive components.
Wikidata — the structured data project behind Wikipedia — has a public query service. I directed Claude to write a SPARQL query filtering for films classified as horror with an IMDB ID. The query returned every horror film in Wikipedia meeting those criteria: 14,932 rows exported as CSV. A seed script parsed the CSV and inserted 12,847 valid records into the database at roughly 47 per second. Each record contained an IMDB ID, title, year, and sometimes a director. Everything else — poster, synopsis, ratings, streaming availability — was empty.
Then the enrichment pipeline begins. Each title gets progressively enriched through multiple API sources, run by natural language commands via Claude Code in the terminal:
OMDB fills metadata: poster, synopsis, ratings, director, genres, runtime. Free tier, 1,000 calls per day, rate-limited at 100ms between requests. Enriching the full catalog takes days.
Watchmode adds streaming sources: which services carry it, deep links, subscription vs. rental vs. purchase, pricing. Credit-based billing at roughly 1,000 free credits per month. This is where the --in-lists flag matters: curated list titles get enriched first so the product is usable while the long tail processes.
TMDB provides trailers and keywords used to generate similar-film recommendations via Jaccard similarity scoring, a method for measuring overlap between keyword sets.
The enrichment script has granular controls: --limit 200, --dry-run, --omdb-only, --watchmode-only, --in-lists. Targeted passes without burning credits unnecessarily. The budget constraint from the PRD became a design feature.
Where AI-Assisted Development Breaks Down
On January 26, I made 12 commits. Every one addressed authentication. The sequence:
Password plus magic link dual auth. Magic links failed — switched to password-only. Passwords broke on first login. Switched to magic link only. Magic links broke on a PKCE code verifier issue. Switched to implicit auth flow. Session persistence broke. Switched to cookie-based session management. Removed middleware auth check entirely. Finally stabilized.
The root cause: Supabase's authentication patterns had changed between versions, and Claude's training data included patterns from older versions. The middleware approach that should have worked was breaking session persistence in the current version of the library.
This is the most important lesson of the entire build. AI is excellent at generating code. Authentication is where version mismatches become dangerous. The fix didn't come from trying more patterns. It came from understanding why the pattern was failing, which required reading the actual Supabase documentation, not generating more code.
The eventual solution works: PKCE flow with magic links, cookie management via @supabase/ssr, a session refresh function with a critical constraint. But it left technical debt: admin routes relying on client-side auth checks, an admin email whitelist duplicated in four files, cookie errors silently suppressed. It ships. It works. It carries scars.
Real products have scars. Anyone who claims otherwise hasn't shipped.
Phase 3: The Features That Made It Real
SEO at Scale
Every film in the database gets its own URL: /film/the-thing-1982. Slugs are auto-generated via a database trigger on insert. Each page is server-rendered on first request, then cached for 24 hours using Next.js Incremental Static Regeneration. Films in curated lists are pre-rendered at build time; everything else renders on demand.
Each film page receives full SEO treatment: meta tags, Open Graph tags, Twitter cards, and JSON-LD structured data using the Movie schema, including streaming WatchActions so Google can surface "Watch on Shudder" directly in search results.
A pragmatic constraint emerged: generating a sitemap for 10,000+ films exceeded the Vercel serverless function timeout. The solution was limiting the sitemap to films in curated lists only. All other films remain accessible and indexable via internal links but aren't explicitly in the sitemap. A trade-off that works.
Ghost Host: AI Inside an AI-Built Product
The most technically ambitious feature, and the most recursive: I used Claude to build a feature powered by Claude.
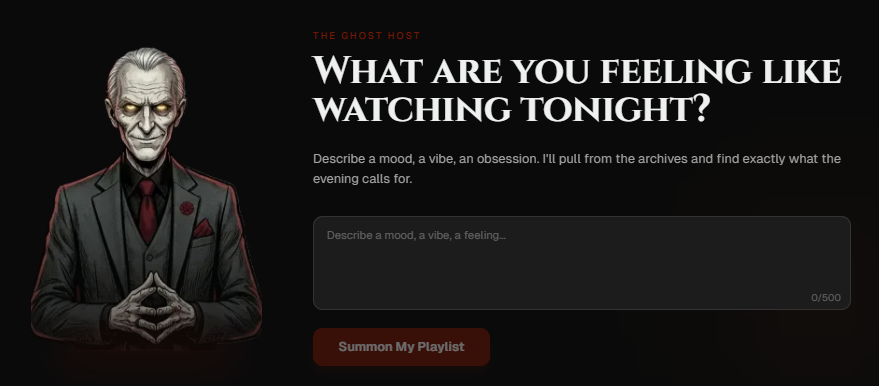
Ghost Host is a mood-based film recommendation engine. A user describes what they want — "giant monster movies, but they have to be smart" — and receives a curated playlist of 15–20 films matched against the catalog with live streaming links.
The character has a defined voice. A 30-line system prompt establishes personality: wry, confident, concise, never condescending. It uses genre vocabulary naturally: giallo, cosmic dread, body horror, Eurohorror. Because the audience expects literacy, not marketing copy. Error messages stay in character.
The technically significant piece is the three-pass matching system. When Claude recommends a film, it returns a TMDB ID. But Claude sometimes hallucinates IDs — returning the ID for one film when it meant another. Pass 1 runs a trigram similarity check on the title to verify the match is correct. Pass 2 handles mismatches: fuzzy title search with year tolerance, scored by string similarity. Pass 3, for stubborn cases, uses Brave Search to find the correct TMDB ID by querying the web, extracting the ID from the URL. Capped at three Brave API calls per request to control costs.
Films that don't match get logged in an unmatched table with a counter tracking request frequency. That counter drives catalog expansion: demand signals, not guesswork.
After matching, each film's streaming sources are checked for freshness. Films with no available sources are dropped. The full orchestration — input validation, auth, rate limiting, Claude API call, three-pass matching, streaming resolution, playlist assembly, session save — happens in a single API route. If the database write fails, the user still gets results. Graceful degradation, not brittle perfection.
What This Reveals (The Replicable Framework)
1. Write the documents first.
Four documents before any code: strategic analysis, PRD, wireframes, implementation guide. The PRD's TypeScript interfaces were implemented nearly verbatim. The budget constraint became a feature. The non-goals prevented scope creep. Every hour of planning saved ten hours of building. This is not overhead. This is the foundation.
2. Specificity is the skill.
The quality of AI output is directly proportional to the precision of the input. Vague prompts produce vague code. Detailed prompts, with file paths, prop types, color values, and interaction specifications, produce components you can ship. This mirrors a principle any experienced product leader understands: the spec is the product.
3. Authentication will break.
This is where AI-assisted development is weakest, because auth patterns change between library versions and AI training data lags behind reality. Read the actual documentation. Understand why the pattern works, not just what the pattern is. This is the one area where AI cannot substitute for direct engagement with the source material.
4. Write handoff documents after every session.
Claude Code has no persistent memory between sessions. Maintaining a comprehensive handoff document, with architecture, database schema, API routes, known issues, and a troubleshooting guide, transforms every new session from a 30-minute re-explanation into immediate productivity. The documentation is part of the build, not separate from it. Claude will write it for you every time, if you ask.
5. Budget constraints are design constraints.
The 1,000 free Watchmode credits forced a priority enrichment system. The Vercel serverless timeout forced a smarter sitemap strategy. The Brave Search API cost forced a three-call cap per recommendation request. In every case, the constraint produced a better design than unlimited resources would have.
6. Ship with scars.
The admin email whitelist is duplicated in four files. Cookie errors are silently suppressed. A feature was fully built but blocked by middleware issues for weeks. The auth system went through ten approaches before stabilizing. Ghost Guide works. It serves real users. It's live at ghostguide.co. Perfection is the enemy of shipping.
The Stack
Next.js 16, React 19, TypeScript, Supabase (PostgreSQL + Row Level Security), TailwindCSS, React Query, Vercel. Anthropic API for Ghost Host. Brave Search for title disambiguation. OMDB, TMDB, and Watchmode for data. Wikidata for the initial 14,932-film seed. 112 commits across roughly 20 active build days.
What This Means
Ghost Guide started as a question I kept hearing from my audience: where can I watch this? It became a production application with over 15,000 titles, real-time streaming data, an AI recommendation engine, and thousands of SEO-optimized pages. I built it in the gaps between client work, over 10 weeks, without writing code.
But I didn't build it without expertise. I brought 25 years of understanding how content platforms work: the data models, the enrichment pipelines, the editorial workflows, the user experience patterns. Claude brought the ability to translate that understanding into a working application.
The combination of deep domain knowledge plus AI execution represents a genuine shift in how products get built. It doesn't replace developers. It creates a new category of builder: the person who knows exactly what should exist, and now has the tools to make it exist.
The barrier between "I know what this should be" and "it's live" has never been lower. Not zero — you still need to think clearly, plan thoroughly, and push through the days when authentication breaks for the twelfth time. But the gap has narrowed dramatically, and it will continue to narrow.
If you're sitting on domain expertise and a product idea, the tools are ready.
Ghost Guide is live at ghostguide.co. Ghosts in the Machine is at ghostsmachine.substack.com. Get in touch with me at nick@graylinegroup.com.